Anatomy of RAG Systems
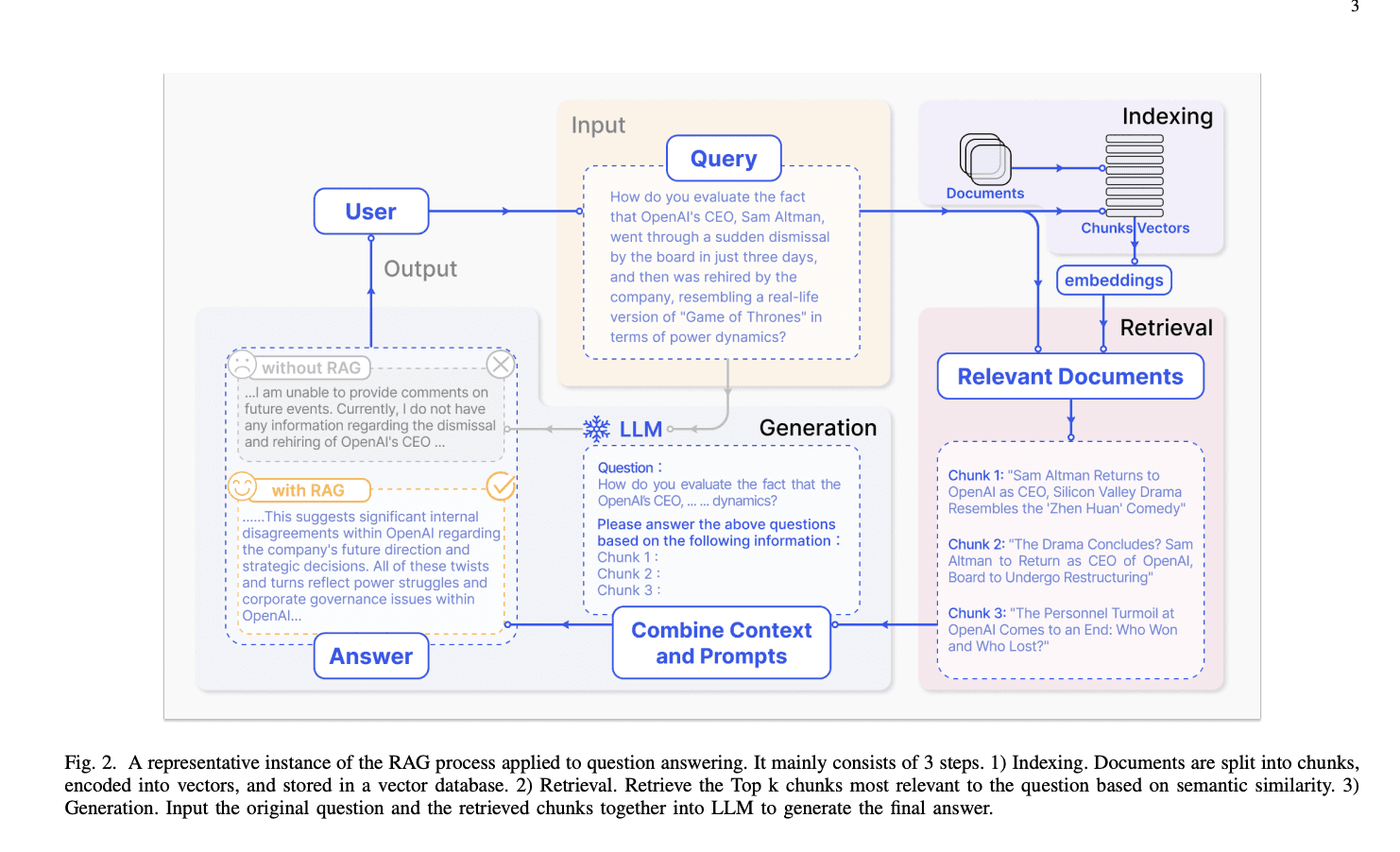
Core Components
1. Document Processor
Handles the initial processing of documents from various sources and formats into a standardized text format.
- Document ingestion and parsing: Imports and reads documents from different sources
- Text extraction and cleaning: Removes noise and standardizes text format
- Metadata extraction: Captures important document properties and attributes
- Format handling: Processes various file types like PDF, HTML, and TXT
- Document validation: Ensures quality and completeness of processed documents
- Error handling: Manages failed document processing gracefully
2. Chunking Engine
Splits documents into manageable pieces while preserving context and meaning.
- Text segmentation strategies: Methods to divide text while maintaining coherence
- Overlap management: Controls how chunks share context with adjacent sections
- Chunk size optimization: Balances context preservation with processing efficiency
- Semantic chunking: Splits text based on meaning rather than fixed sizes
- Metadata preservation: Maintains document properties across chunk boundaries
- Document structure preservation: Maintains hierarchical relationships
- Cross-reference handling: Manages internal document references
3. Embedding Generator
Converts text chunks into numerical vectors that capture semantic meaning.
- Vector representation creation: Transforms text into mathematical vectors
- Embedding model selection: Chooses appropriate models for vector generation
- Dimensionality considerations: Optimizes vector size for performance
- Batch processing optimization: Efficiently handles large-scale embedding generation
- Quality assurance checks: Validates embedding quality and consistency
- Model versioning: Tracks embedding model versions
- Embedding validation: Verifies vector quality and consistency
- Error recovery: Handles failed embedding generation
4. Vector Store
Efficiently stores and indexes vector embeddings for quick similarity search.
- Vector database management: Organizes and maintains vector data storage
- Indexing strategies: Optimizes data structure for fast retrieval
- Similarity search algorithms: Implements efficient vector comparison methods
- Metadata filtering: Enables refined search based on document properties
- Performance optimization: Tunes database for speed and efficiency
5. Query Processor
Transforms user queries into optimal formats for retrieval.
- Query understanding: Analyzes and interprets user input
- Query transformation: Converts queries into search-optimized format
- Query expansion: Enhances queries with related terms
- Context window management: Controls scope of query context
- Hybrid search support: Combines different search strategies
6. Retriever
Finds and ranks the most relevant chunks for a given query.
- Relevance scoring: Evaluates chunk similarity to query
- Re-ranking mechanisms: Refines initial search results
- Multi-stage retrieval: Implements layered search strategies
- Context assembly: Combines retrieved chunks coherently
- Filter application: Applies constraints to search results
7. Prompt Manager
Orchestrates the assembly of retrieved context into effective prompts.
- Template management: Maintains standardized prompt structures
- Context injection: Integrates retrieved information into prompts
- System prompts: Manages base instructions for LLM
- Few-shot examples
8. Generator
Produces final responses using LLM with retrieved context.
- LLM integration: Connects with language models
- Response synthesis: Creates coherent answers
- Citation management: Tracks information sources
- Quality control: Ensures response accuracy
- Error handling: Manages generation failures
Advanced Features
Feedback Loop
Continuously improves system performance based on usage patterns and outcomes.
- User feedback collection: Gathers user interaction data
- Performance monitoring: Tracks system effectiveness
- Quality metrics tracking: Measures response quality
- Continuous improvement: Implements system enhancements
- A/B testing: Evaluates system changes
- Model performance tracking: Monitors embedding and retrieval quality
- User interaction analysis: Studies query patterns and user behavior
- Automated retraining triggers: Identifies when system updates are needed
Caching Layer
Optimizes performance and reduces costs by storing frequent results.
- Response caching: Stores common query results
- Embedding caching: Preserves computed embeddings
- Cache invalidation: Updates outdated cache entries
- Performance optimization: Tunes caching strategies
- Cost management: Balances storage and computation costs
- Multi-level caching: Implements hierarchical caching strategy
- Cache analytics: Monitors cache hit rates and performance
- Resource optimization: Balances memory usage and response time
Security Layer
Ensures data privacy and compliance throughout the RAG pipeline.
- Access control: Manages user permissions
- Data encryption: Protects sensitive information
- PII detection: Identifies personal information
- Audit logging: Tracks system usage
- Compliance checks: Ensures regulatory adherence
- Data lineage tracking: Maintains history of data usage and transformations
- Access patterns monitoring: Detects unusual system usage
- Compliance reporting: Generates audit trails for regulatory requirements
Monitoring & Observability
Provides comprehensive system visibility and performance tracking.
- System health metrics: Monitors component status and performance
- Latency tracking: Measures response times across the pipeline
- Error rate monitoring: Tracks failure points and recovery
- Resource utilization: Monitors compute and storage usage
- Cost analytics: Tracks operational expenses
Data Quality Control
Ensures high-quality input and output throughout the pipeline.
- Input validation: Verifies document quality and format
- Content filtering: Removes inappropriate or irrelevant content
- Output verification: Validates response quality and accuracy
- Source credibility: Evaluates information source reliability
- Version control: Manages document and embedding versions