🛡️
Running production systems? Exemplar brings SRE, uptime monitoring, and incident management together so your team resolves outages faster and proves reliability to the business. Visit exemplar.dev →
Paradigms of RAG Architectures
RAG Overview
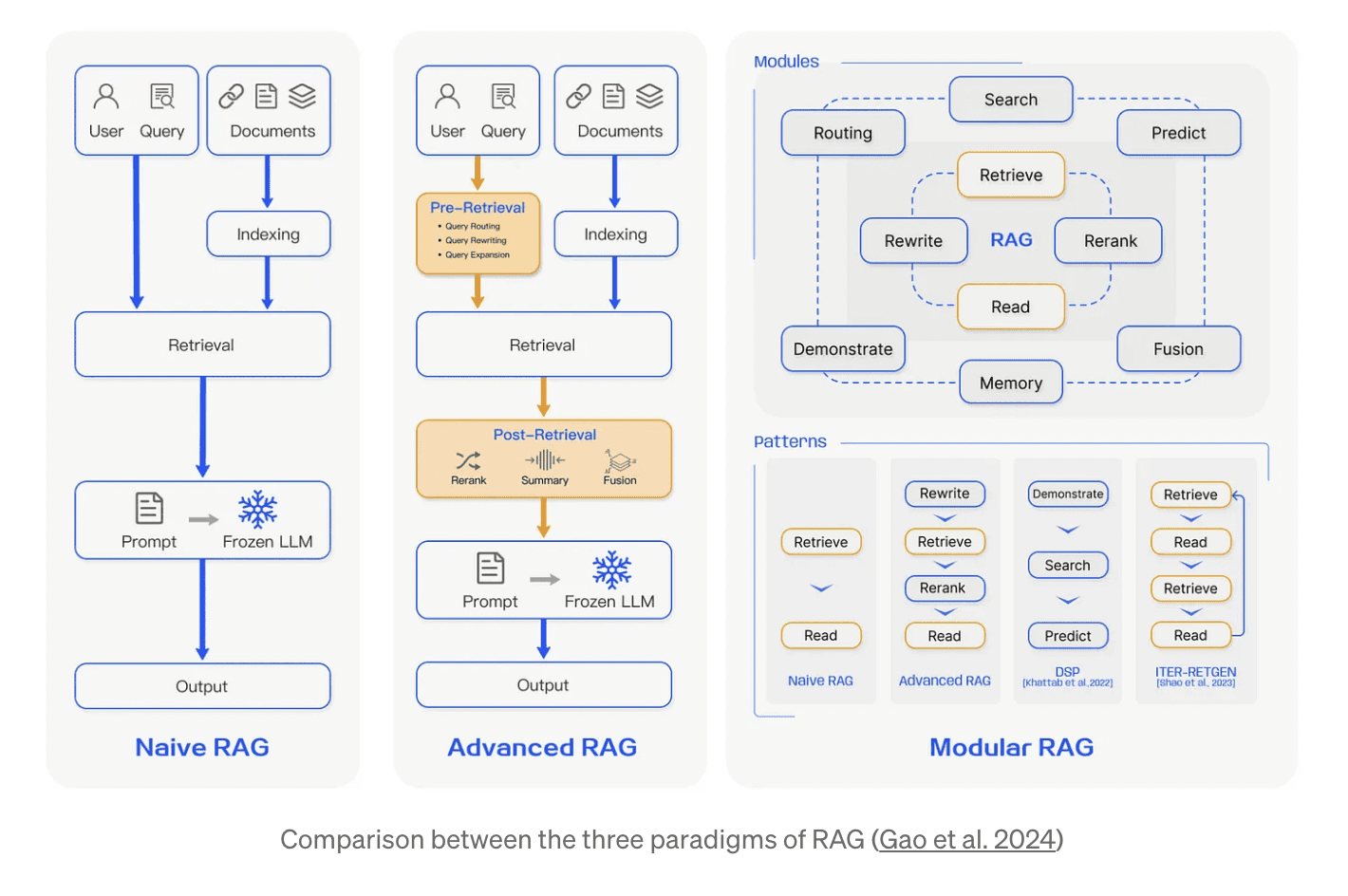
1. Naive RAG
The simplest form of RAG implementation that follows a basic workflow:
- Document ingestion and chunking
- Vector embedding generation
- Similarity search
- Context injection into prompts
- LLM response generation
Limitations
- Basic retrieval methods
- Limited context understanding
- No quality control mechanisms
- Potential for irrelevant retrievals
2. Advanced RAG
Builds upon Naive RAG with sophisticated features:
Key Enhancements
- Multi-vector retrieval
- Hybrid search methods
- Re-ranking mechanisms
- Query transformations
- Dynamic context windows
Benefits
- Improved retrieval accuracy
- Better context relevance
- Enhanced response quality
- Reduced hallucinations
3. Modular RAG
A flexible, component-based approach:
Core Modules
- Pre-retrieval Module: Query understanding and transformation
- Retrieval Module: Multi-stage document fetching
- Post-retrieval Module: Context processing and optimization
- Generation Module: Response synthesis and verification
Advanced Features
- Parent-child document relationships
- Semantic routing
- Auto-metadata generation
- Dynamic system prompts
- Recursive retrieval patterns
Comparison Table
| Feature | Naive RAG | Advanced RAG | Modular RAG |
|---|---|---|---|
| Complexity | Low | Medium | High |
| Accuracy | Basic | Improved | Highest |
| Flexibility | Limited | Moderate | Highly Flexible |
| Implementation | Simple | Moderate | Complex |
| Maintenance | Easy | Medium | Requires Expertise |
Challenges in Retrieval Augmented Generation
- Data Relevance: Ensuring high relevance of retrieved documents.
- Latency: Managing overhead from searching external sources.
- Data Quality: Avoiding inaccuracies from low-quality data.
- Scalability: Handling large datasets and high traffic.
- Security: Ensuring data privacy and secure handling of sensitive information.